
Nvidia GPUs have made significant advancements, not only in gaming performance but also in various applications, particularly artificial intelligence, and machine learning with their GPUs. The GPU performance of NVIDIA can be attributed to two primary factors: CUDA and Tensor cores, which are found in nearly all modern GPUs.
But what exactly is the role of these cores, and how do they differ?
CUDA cores were introduced in 2014 and excel in parallel processing, making them ideal for tasks such as cryptographic hashes, physics engines, data science, and game development. While they enhance gaming performance, they are primarily designed for graphical processing.
Tensor cores, on the other hand, were introduced in 2017 for AI and machine learning workloads. They were optimized to handle matrix multiplication at a significantly faster rate compared to CUDA cores. Although Tensor cores sacrifice some accuracy, they offer superior computational speed and cost-effectiveness for training machine learning models.
In short, CUDA cores specialize in handling graphical workloads, while Tensor cores are better at numerical ones.
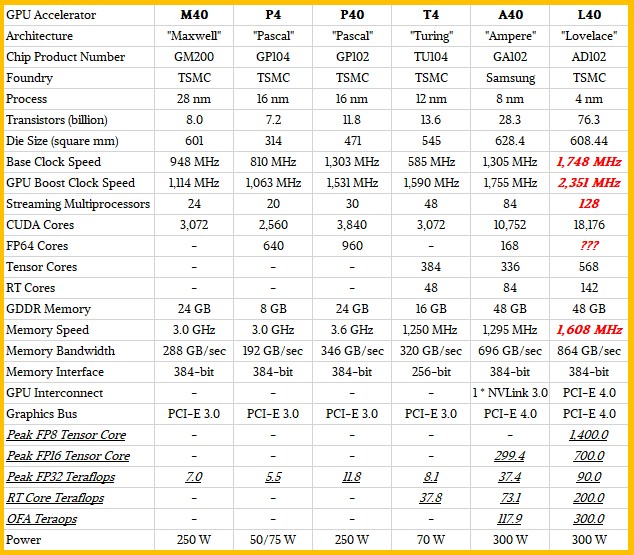
The number and composition of CUDA and Tensor cores in a GPU vary. For example, consumer gaming GPUs like the RTX 4090 have a higher number of CUDA cores (16,384) compared to Tensor cores (512). In contrast, data center GPUs like the Nvidia L40 have a higher count of both CUDA cores (18,176) and Tensor cores (568), resulting in significantly improved performance for specialized tasks.
In terms of theoretical performance, the L40 GPU outperforms the RTX 4090 in terms of floating-point operations per second (TFlops) for various precision levels (FP16, FP32, FP64). These differences in core composition directly impact the overall performance of the GPUs.
Late last year, when NVIDIA introduced the L40 and L4 datacenter GPUs. The L is short for Ada Lovelace, also known as Lovelace, serving as the successor to the Ampere-based architecture. The ampere architecture came out in early 2020, and there have been significant improvements over the older architecture with the Lovelace architecture.
With L4 and L40 this are the current stats for the different cards:
- NVIDIA L40
- FP32 Cores per GPU: 18,176
- Tensor Cores per GPU: 568
- RT Cores per GPU: 142
- Total Memory Size per GPU: 48 GB GDDR6
- Peak memory bandwidth 864 GB/s
- RT Core performance 209 TFLOPS
- NVIDIA L4
- FP32 Cores per GPU: 7,424
- Tensor Cores per GPU: 232
- RT Cores per GPU: 58
- Total Memory Size per GPU: 24 GB GDDR6
- Peak memory bandwidth 300 GB/s
- RT Core performance 31.33 TFLOPS
Also I really liked the overview that I found here (nvidia-lovelace-l40-compare-table.jpg (634×555) (nextplatform.com) which shows the difference between the different generations of GPU cards over the years.
{kind=link}

The L40 is recommended for vWS workloads (NVIDIA RTX™ Virtual Workstation) since it supports most of the different vGPU profiles. These new cards are now also supported on VMware Horizon VMware Horizon 8 2303 Release Notes and Citrix with the use of vGPU. You can also view the different vGPU profiles that you can use in combination with the L40 cards here Virtual GPU Software User Guide :: NVIDIA Virtual GPU Software Documentation
In previous iterations of vSphere, it was required for all NVIDIA vGPU workloads on an ESXi host to utilize the identical vGPU profile type and GPU memory size.
However, in vSphere 8 U1, NVIDIA vGPUs now can be assigned distinct vGPU profile types. Nevertheless, the GPU memory sizes across all profiles must still remain consistent. As an illustration, the diagram below shows three virtual machines (VMs) with varying vGPU profile types, namely “B, C, and Q,” each having a GPU memory size of “8GB.” This enhancement enables more efficient sharing of GPU resources among diverse workloads

The cool thing is these cards are now available in the latest generation HPE servers (Generation 11) HPE: Your strategic partner for AI | HPE and also available in Google Cloud (well at least the L4 cards) Accelerator-optimized machine family | Compute Engine Documentation | Google Cloud
This can be some options to provide the latest generation NVIDIA cards for your VDI workloads, this is a show case demo from Frame with using the NVIDIA L4 card on Google Cloud GCPG2-STD-8-GPU-L4_ZSSDPD_NLD_WAN_100Mb_0ms_FRP8_UDP_FGA8770_YUV420_FHD | Frame User Experience Research